
AI a fizyka: wyzwania w symulacji odbić i praw fizycznych
Od momentu, gdy generatywna sztuczna inteligencja wzbudziła szerokie zainteresowanie, badacze zajmujący się komputerowym przetwarzaniem obrazu skupili się na rozwijaniu modeli AI, które potrafią zrozumieć i odtwarzać prawa fizyki. Jednak nauczenie systemów uczenia maszynowego symulowania zjawisk takich jak grawitacja czy dynamika płynów pozostaje kluczowym wyzwaniem od co najmniej pięciu lat.
Od czasu, gdy modele latentnej dyfuzji (LDMs) zdominowały scenę generatywnej AI w 2022 roku, naukowcy coraz częściej zwracają uwagę na ich ograniczenia w rozumieniu i odtwarzaniu zjawisk fizycznych. Temat ten zyskał na znaczeniu wraz z przełomowym rozwojem modelu generującego filmy Sora autorstwa OpenAI oraz – być może jeszcze ważniejszym – wydaniem otwartych modeli wideo, takich jak Hunyuan Video czy Wan 2.1.
Problemy z odbiciami
Większość badań nad poprawą zdolności LDMs do rozumienia fizyki koncentrowała się na symulacji chodu, fizyce cząstek i innych aspektach ruchu newtonowskiego. Obszary te przyciągnęły uwagę, ponieważ błędy w podstawowych zachowaniach fizycznych natychmiast podważają wiarygodność generowanych filmów.
Jednak coraz więcej badań skupia się na jednej z największych słabości LDMs – ich ograniczonej zdolności do tworzenia realistycznych odbić.

Przykłady 'nieudanych odbić' oraz podejście badaczy z pracy 'Reflecting Reality: Enabling Diffusion Models to Produce Faithful Mirror Reflections'. Źródło: https://arxiv.org/pdf/2409.14677
Problem ten był wyzwaniem już w erze CGI i pozostaje nim w branży gier wideo, gdzie algorytmy ray-tracingu symulują drogę światła odbijającego się od powierzchni. Ray-tracing oblicza, jak wirtualne promienie światła odbijają się lub przechodzą przez obiekty, tworząc realistyczne odbicia, załamania i cienie.
Jednak każdy dodatkowy odbicie znacząco zwiększa koszty obliczeniowe, dlatego aplikacje działające w czasie rzeczywistym muszą balansować między opóźnieniami a dokładnością, ograniczając liczbę odbić.

Wizualizacja wirtualnie obliczonej wiązki światła w tradycyjnym scenariuszu CGI, wykorzystującym technologie rozwijane od lat 60. XX wieku. Źródło: https://www.unrealengine.com/en-US/explainers/ray-tracing/what-is-real-time-ray-tracing
Na przykład, przedstawienie chromowanego czajnika przed lustrem wymagałoby wielokrotnych odbić promieni między powierzchniami, tworząc niemal nieskończoną pętlę, która niewiele wnosi do końcowego obrazu. W większości przypadków głębokość odbić rzędu dwóch-trzech odbić przekracza już to, co widz może dostrzec. Jedno odbicie dałoby czarne lustro, ponieważ światło musi przebyć drogę przynajmniej dwukrotnie, aby powstało widoczne odbicie.
Każde dodatkowe odbicie znacząco zwiększa koszty obliczeniowe, często podwajając czas renderowania, dlatego szybsze przetwarzanie odbić jest jedną z najważniejszych szans na poprawę jakości renderowania z ray-tracingiem.
Odbicia występują – i są kluczowe dla fotorealizmu – także w mniej oczywistych scenariuszach, takich jak mokra ulica, odbicie przeciwległej ulicy w witrynie sklepowej czy w okularach przedstawionych postaci.

Symulowane podwójne odbicie osiągnięte tradycyjnymi metodami kompozycji w kultowej scenie z 'Matrixa' (1999).
Problemy z obrazem
Z tego powodu frameworki popularne przed erą modeli dyfuzyjnych, takie jak Neural Radiance Fields (NeRF), oraz nowsze rozwiązania, np. Gaussian Splatting, również borykają się z realistycznym odtwarzaniem odbić.
Projekt REF2-NeRF (pokazany poniżej) zaproponował metodę modelowania scen z szklanymi gablotami, wykorzystującą elementy zależne i niezależne od perspektywy obserwatora. Pozwoliło to na oszacowanie powierzchni, gdzie występuje załamanie światła, oraz na oddzielenie i modelowanie zarówno światła bezpośredniego, jak i odbitego.

Przykłady z pracy Ref2Nerf. Źródło: https://arxiv.org/pdf/2311.17116
Inne rozwiązania dla NeRF dotyczące odbić z ostatnich lat obejmują NeRFReN, Reflecting Reality oraz projekt Meta z 2024 roku pt. Planar Reflection-Aware Neural Radiance Fields (link).
W przypadku GSplat, prace takie jak Mirror-3DGS, Reflective Gaussian Splatting czy RefGaussian oferują rozwiązania problemu odbić, podczas gdy projekt Nero z 2023 roku zaproponował własną metodę włączania właściwości odbiciowych do reprezentacji neuronowych.
MirrorVerse
Nauczenie modelu dyfuzyjnego respektowania logiki odbić jest prawdopodobnie trudniejsze niż w przypadku wyraźnie strukturalnych, niesemantycznych podejść, takich jak Gaussian Splatting czy NeRF. W modelach dyfuzyjnych reguła tego rodzaju może zostać wiarygodnie osadzona tylko wtedy, gdy dane treningowe zawierają wiele różnorodnych przykładów z szerokiego zakresu scenariuszy, co czyni ją silnie zależną od jakości i dystrybucji oryginalnego zbioru danych.
Tradycyjnie dodawanie tego typu zachowań jest domeną LoRA lub dostrajania modelu bazowego, ale nie są to idealne rozwiązania. LoRA może wypaczać wyniki w kierunku swoich danych treningowych, nawet bez odpowiednich podpowiedzi, a dostrojenia – poza tym, że są kosztowne – mogą odchylić główny model od mainstreamu i wymusić użycie narzędzi, które nie będą działać z innymi wersjami modelu.
Ogólnie rzecz biorąc, poprawa modeli dyfuzyjnych wymaga, aby dane treningowe uwzględniały fizykę odbić. Jednak wiele innych obszarów również potrzebuje podobnej uwagi. W kontekście ogromnych zbiorów danych, gdzie niestandardowa selekcja jest kosztowna i trudna, rozwiązanie każdej słabości w ten sposób jest niepraktyczne.
Mimo to rozwiązania problemu odbić w LDMs pojawiają się od czasu do czasu. Jednym z nich jest projekt MirrorVerse z Indii, który oferuje ulepszony zbiór danych i metodę treningową, mogącą poprawić obecny stan techniki w tym wyzwaniu.

Po prawej wyniki MirrorVerse w porównaniu z dwoma wcześniejszymi podejściami (środkowe kolumny). Źródło: https://arxiv.org/pdf/2504.15397
Jak widać na powyższym przykładzie (główny obraz w PDF nowego badania), MirrorVerse poprawia się w stosunku do ostatnich propozycji rozwiązujących ten sam problem, ale daleko mu do perfekcji.
W prawym górnym obrazie widać, że ceramiczne dzbany są nieco bardziej na prawo, niż powinny, a na obrazie poniżej, który technicznie nie powinien zawierać odbicia kubka, niedokładne odbicie zostało "wciśnięte" w prawą część, wbrew logice naturalnych kątów odbicia.
Dlatego przyjrzymy się nowej metodzie nie tyle dlatego, że może reprezentować obecny stan techniki w generowaniu odbić, ale także aby zilustrować, jak bardzo może to być nierozwiązywalny problem dla modeli latentnej dyfuzji – zarówno statycznych, jak i wideo – ponieważ wymagane przykłady odbić są najprawdopodobniej powiązane z konkretnymi akcjami i scenariuszami.
Z tego powodu ta konkretna funkcjonalność LDMs może nadal pozostawać w tyle za podejściami strukturalnymi, takimi jak NeRF, GSplat, a także tradycyjne CGI.
Nowa praca nosi tytuł MirrorVerse: Pushing Diffusion Models to Realistically Reflect the World i pochodzi od trzech badaczy z Vision and AI Lab, IISc Bangalore oraz Samsung R&D Institute w Bangalore. Praca ma stronę projektu, a także zbiór danych na Hugging Face i kod źródłowy dostępny na GitHubie.
Metoda
Badacze zauważają od razu trudność, jaką modele takie jak Stable Diffusion czy Flux mają z respektowaniem podpowiedzi dotyczących odbić, ilustrując problem trafnie:

Z pracy: Obecne modele tekst-obraz, SD3.5 i Flux, wykazują znaczące trudności w tworzeniu spójnych i geometrycznie dokładnych odbić, gdy są proszone o ich wygenerowanie w scenie.
Badacze opracowali MirrorFusion 2.0, generatywny model oparty na dyfuzji, mający na celu poprawę fotorealizmu i dokładności geometrycznej odbić w lustrach w syntetycznych obrazach. Trening modelu opierał się na nowo przygotowanym przez badaczy zbiorze danych MirrorGen2, zaprojektowanym, aby zaradzić słabościom generalizacji obserwowanym w poprzednich podejściach.
MirrorGen2 rozszerza wcześniejsze metodyki, wprowadzając losowe pozycjonowanie obiektów, losowe obroty oraz jawne zakotwiczenie obiektów, aby zapewnić, że odbicia pozostaną wiarygodne w szerszym zakresie pozycji i ustawień obiektów względem powierzchni lustra.
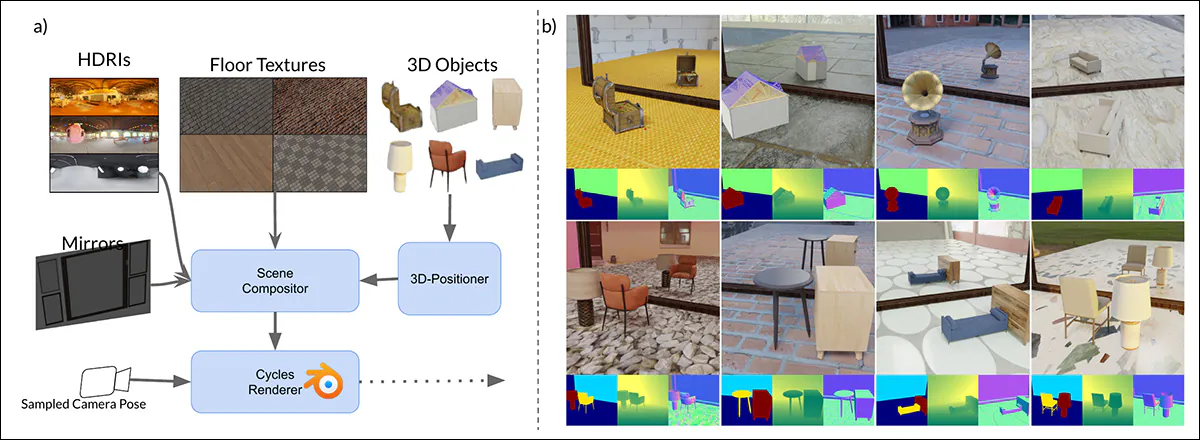
Schemat generowania syntetycznych danych w MirrorVerse: pipeline generowania zbioru danych zastosował kluczowe augmentacje poprzez losowe pozycjonowanie, obracanie i zakotwiczanie obiektów w scenie przy użyciu 3D-Positioner. Obiekty są również łączone w semantycznie spójne pary, aby symulować złożone relacje przestrzenne i przesłonięcia, pozwalając zbiorowi danych uchwycić bardziej realistyczne interakcje w scenach z wieloma obiektami.
Aby dodatkowo wzmocnić zdolność modelu do radzenia sobie ze złożonymi układami przestrzennymi, pipeline MirrorGen2 zawiera sceny z parowanymi obiektami, umożliwiając systemowi lepsze reprezentowanie przesłonięć i interakcji między wieloma elementami w scenach z odbiciami.
W pracy stwierdzono:
Kategorie są ręcznie parowane, aby zapewnić spójność semantyczną – na przykład krzesło z stołem. Podczas renderowania, po ustawieniu i obróceniu głównego [obiektu], dodatkowy [obiekt] z sparowanej kategorii jest próbkowany i układany tak, aby uniknąć nakładania się, zapewniając odrębne regiony przestrzenne w scenie.
W przypadku jawnego zakotwiczenia obiektów autorzy zapewnili, że generowane obiekty były "zakotwiczone" do podłoża w wynikowych danych syntetycznych, zamiast "unosić się" w niewłaściwy sposób, co może się zdarzyć, gdy dane syntetyczne są generowane na dużą skalę lub wysoce zautomatyzowanymi metodami.
Ponieważ innowacje w zbiorze danych są kluczowe dla nowości pracy, przejdziemy do tej sekcji wcześniej niż zwykle.
Dane i testy
SynMirrorV2
Zbiór danych SynMirrorV2 badaczy został stworzony, aby poprawić różnorodność i realizm danych treningowych dotyczących odbić w lustrach, zawierając obiekty 3D pochodzące ze zbiorów Objaverse i Amazon Berkeley Objects (ABO), z selekcją dodatkowo dopracowaną przez OBJECT 3DIT oraz proces filtrowania z projektu MirrorFusion V1, aby wyeliminować niskiej jakości zasoby. W rezultacie uzyskano dopracowaną pulę 66 062 obiektów.

Przykłady ze zbioru danych Objaverse, użytego do stworzenia wyselekcjonowanego zbioru danych dla nowego systemu. Źródło: https://arxiv.org/pdf/2212.08051
Konstrukcja scen obejmowała umieszczanie tych obiektów na teksturowanych podłogach z CC-Textures i tłach HDRI z repozytorium CGI PolyHaven, z wykorzystaniem luster pełnościennych lub wysokich prostokątnych. Oświetlenie było ustandaryzowane z obszarowym światłem umieszczonym nad i za obiektami pod kątem 45 stopni. Obiekty były skal